Regular Expressions - 2 tips for maintainability
This transcript is from our monthly internal Tech Talks sessions - presented by Nigel Ramsay.
Today I'm talking about regular expressions, and I've got two tips for maintainability. These are two learnings that Santosh and I discovered as part of our work with Addressfinder, enhancing the address verification algorithms for Australia.
The two tips are the multi-line option and named captures. I'll give some examples, and I'll talk about how it’s used.
So first up I've got a regular expression which is going to be our base regular expression. This is a regular expression that did exist, in source code. And we've pulled it out, it’s been tweaked a little bit for the presentation.

It's trying to identify, a particular type of phrase that's within some text. And in this example, it's trying to identify a "unit type" and then some numbers. So an example that might be Unit 17 or Unit 205 or Flat 19 or Flat 19a .
I show an example here where there's some sample text nigel ramsay unit 44 hahaha.
If you've ever worked with me, you'll recognise "hahaha". This regular expression at the moment does extract out those elements, but it's a bit hard to read. I'm not sure about the non-technical people here, you're probably thinking "I wonder what's going on here". It's more complicated - I think this is actually classic of regular expressions in general, especially when you encounter a regular expression that another person has written, and you're looking and thinking "I wonder what this is about". And, you know, there's lots of like special control characters and that sort of thing. We do recognise some of them, but it takes quite a bit of brain power to work it out.
Tip 1: the multi-line option
Let's have a look at the multi-line option.

To add this, you add a "slash x" on the end of your regular expression. And what that does is it tells the regex engine to ignore all whitespace.
Here's an example, I've taken the previous example and I've appended a "slash x" on it.

And you can see we can, you can get the regex to flow all across multiple lines. So one thing you have to be aware of is that back in that previous example, we did have some important whitespace in here. So we need to keep an eye on that.
I've just converted those space characters from the previous version into a \s. I know that \s is a bit more generous than just a space character, but that's fine for our purposes. So what that lets us do is have the important elements on separate lines. So it's quite a lot easier to read, which is great.
Embedding comments into the regular expression
And then you can also put comments against each line. The comments get ignored by the regex parser.

For example, if we talk about that regular expression, there's a leading prefix - which this .* represents. And then we've got a series of unit types, such as "unit", "apartment" or "shop". In the real example, there's actually about 20 or 30 of them.
Then, there's a mandatory space. Followed by some digits or letters \w+. And I give an example of "10b", for example. Then some more optional white space and then anything else.
So you can see you can have multiple line comments as well if you want to. There's plenty of room to make it that much easier for like the next developer who's looking at your code, to have a look at it, and not to spend a lot of time thinking about it.
Iterative regular expression development with Rubular.com
There's a website called rubular.com which allows you build up regular expressions, interactively and try them out with real examples.
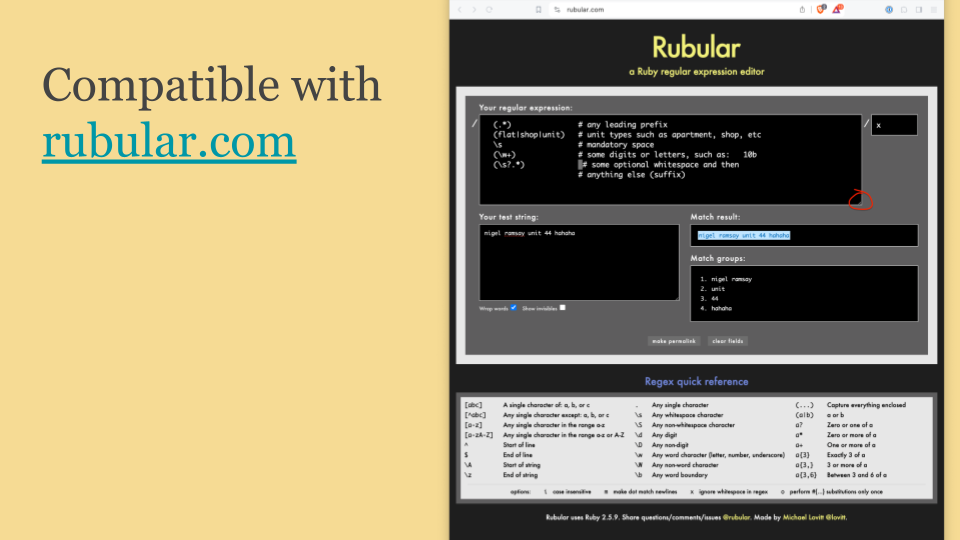
You can see here that I've taken that code and copied and pasted it into into the box. Now on Rubular, normally this box is a single line, but the text field has an expansion control that you can grab and you drag down, expanding to have multiple lines. You paste it right in there and it works, and it's identifying the matches.
Tip 2: named captures
What is a capture?

Captures allow you to extract elements from a string, and they're normally numbered. So in the previous example we had brackets around each one of those elements - the brackets indicate it's a capture. So when you pass a string through the regular expression, you pull out a portion of that string, one part at a time.
And normally you have to pull them out with an index. So the first one is "index one", the second is "index two", the third is "index three". But named captures allow you to write labels, rather than extracting by number. You can say, this capture here is going to be called the "prefix". And, this other capture is going to be called the "suffix".
It's one step toward making it like a little bit easier.

So I've taken the previous example and I've added some code to show how it's being used. You can see that I'm kind of pulling out the portions. So for example, the "unit type" and "identifier" is match number two and match number three. And that matches the dark pink colour up above.
How to define a named capture
So, let's try out a named capture. How do we make a name capture?

We take the brackets that we previously had, we pull them apart and add question mark, as well as label between greater than, and less than signs.
Let's look at an example - I've taken that previous regex and I've named the "prefix", "unit type", "unit identifier" and "suffix".

Now the cool thing about the labels is that I've been able to truncate my comments a little, as the label is providing part of the comment about what's going on. I don't have to make mention of the prefix in the comment, as the label is now indicating that it's the prefix.
So here's the code example of this being used:

We can now kind of pull out the different elements as they are named. It's a little easier to read. Like in the first tip, it just makes it a little easier for the next person who's maintaining your code.
If you're doing some maintenance of the regular expression, and what was "index one" is now "index two" because you added an additional capture in the middle. These labels will stay the same, which is great.
Named captures are visible with Rubular.com
Finally, these named captures are also compatible with Rubular.com.
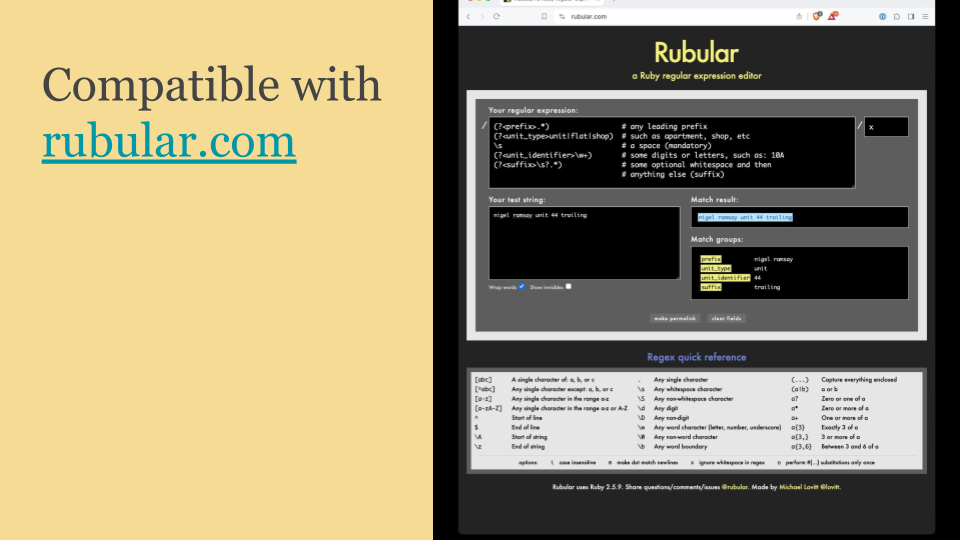
You can see the capture groups are now displayed with labels. You can see the prefix, the unit type, the unit identifier, and the trailing suffix.
Summary
In summary, the multi-line option with /x gives you like improved readability. You can define inline comments, on multi lines as well.
The name captions allow you to extract data without needing the offsets. They contribute to making the documentation a little bit better.
And finally, using Rubular.com makes working with regular expressions awesome.